Xavier Theimer-Lienhard
Reasoning finetuning of Meditron models
What are reasoning models?
Relying on the same idea as Chain of Thought (COT), reasoning models 'think' for longer and have better performance on hard tasks that require reasoning, even better performances than COT. These models rather than being prompted to 'think step by step' at inference (the COT method), are trained to have a thinking phase before the output phase. The thinking phase is quite similar to what COT output looks like, though sometimes it goes even farther, checking on its previous assertions, and repeating itself multiple times. It also often is longer than COT output.Openai are the first to have used reasoning models, with their breakthrough model o1, followed by Deepseek R1. At the time of writing, the top performing models, Gemini-2.5 and o3, are reasoning models.
Why Meditron?
Reasoning models are LLMs specifically designed not just to recall information, but to solve problems through transparent step-by-step analysis. In the context of medicine, these models provide transparent rationales for their answers, which is essential for clinical trust and accountability. Reasoning models aim to handle complex cases by showing their thought process, rather than providing only final answers.How are reasoning models trained?
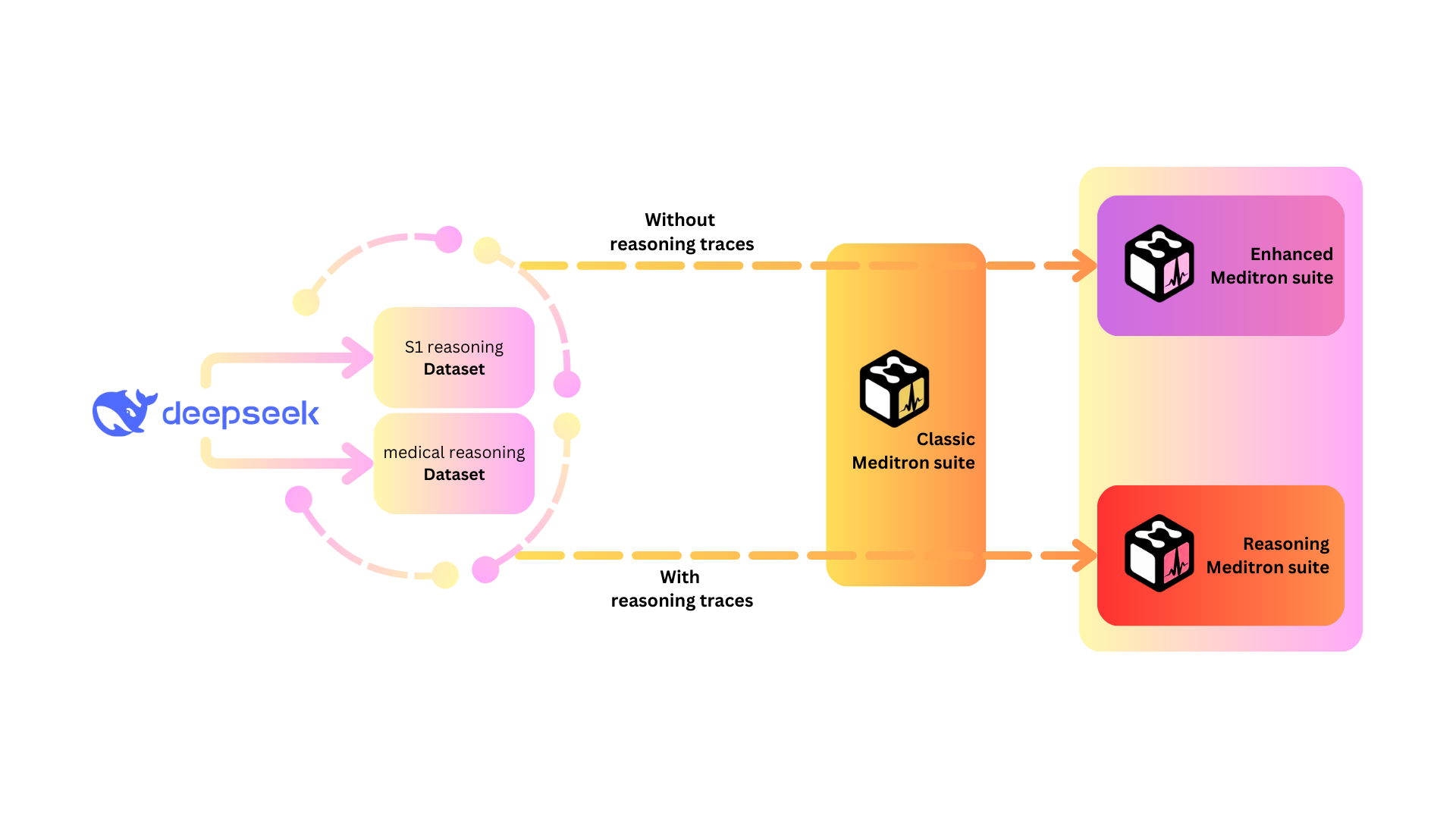
To train reasoning models, we start with strong medical LLMs—here, Meditron-8b (based on Llama-3.1-8B) and Medicouenne-7b (based on Qwen-2.5-7B)—and further finetune them using small, high-quality reasoning datasets. The training setup involved two main variables: - **Dataset type**: General-purpose reasoning (S1.1), medical-specific reasoning (Medical-QA-Reasoning), or a combination of both. - **With or without reasoning traces**: Reasoning traces are the explicit, step-by-step explanations generated by a powerful model (Deepseek-R1). For each dataset, we created two versions: one including these reasoning traces and one with only the final answers (traces removed). Each sample was formatted in a chat-like template, and all training runs used the same hyperparameters and infrastructure (8× NVIDIA H100 GPUs, mixed-precision, 15-minute runs per model). This design resulted in a total of 12 model variants (six per base model).Our results
1. **Reasoning finetuning works**: All reasoning-finetuned models significantly outperformed their base models on reasoning benchmarks (MMLU STEM), improving accuracy by 15–30 points. This shows that even small-scale finetuning can teach Meditron models to reason more effectively. 2. **Dataset quality matters**: For Medicouenne, the best performance came from models trained on the combined dataset. For Meditron, the S1.1 general reasoning dataset alone worked best. The medical-specific dataset, though smaller and less filtered, was still nearly as effective, hinting that specialized data helps, but general reasoning data remains crucial. 3. **Medical performance improves**: Not only did reasoning finetuning boost reasoning benchmarks, but it also improved medical question-answering performance by 5–11 points on generation-based tasks, with no major trade-offs—except for a slight drop in PubMedQA for Medicouenne. 4. **Surprising finding—traces may not help**: Models trained **without** explicit reasoning traces (i.e., using just the answer, not the step-by-step process) actually performed better on most benchmarks. This could be due to the length and noisiness of reasoning traces, which sometimes contain redundant or unclear reasoning steps. 5. **Sustainable and efficient**: Thanks to small datasets and efficient infrastructure, each training run consumed less than 1kg CO₂—thousands of times less than a short airplane flight.Conclusion
Reasoning finetuning, even with small datasets and modest models, can substantially enhance both reasoning and medical performance of Meditron models. Surprisingly, omitting step-by-step traces may yield even better results, though this comes at the expense of interpretability. Ongoing and future work will focus on improving medical-specific reasoning data, scaling to larger models, and evaluating answer fluency with human raters.Appears on
Enhancing Meditron capabilities with synthetic and reasoning datasets
X. Theimer-Lienhard, M. Jaggi, M.-A. Hartley.
Master thesis
Pdf
We improved the Meditron models' step-by-step analytical processes by training on specialized reasoning datasets.
X. Theimer-Lienhard, M. Jaggi, M.-A. Hartley.
Master thesis
We improved the Meditron models' step-by-step analytical processes by training on specialized reasoning datasets.